
Architecting Real-time Speech Interaction: Step-Audio's Approach to Seamless Tool Calling

Building truly intelligent real-time speech interaction systems presents significant technical hurdles. A key challenge arises when the system needs to access external information or services – performing "tool calls" or "API integrations". Traditionally, integrating these steps into a cascading ASR-LLM-TTS pipeline could introduce latency, requiring the system to wait for API responses before generating the final spoken output.
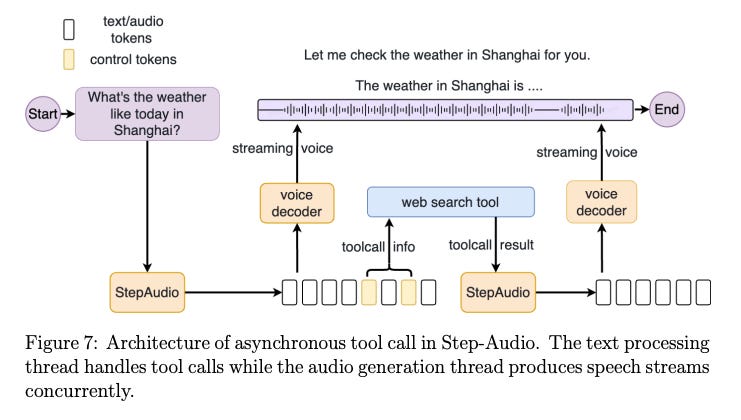
Step-Audio, the first production-ready open-source framework for intelligent speech interaction, addresses this with an innovative asynchronous tool invocation mechanism. Rather than a simple sequential process, the architecture specifically decouples the text-based tool processing from the audio generation pipelines.
Why is this decoupling significant?
Real-time text responses and their corresponding audio streams have a substantial bitrate disparity. By separating the processes, Step-Audio allows for the parallel execution of external service queries (like knowledge retrieval) and speech synthesis.
The result?
This design eliminates waiting time for audio rendering when a tool call is required, significantly enhancing interaction fluidity. The system manages complex tasks by augmenting its cognitive architecture with this crucial tool calling ability.
This architectural choice is a technical leap forward, enabling smoother, more natural conversational dynamics even when the system needs to look up information or interact with external systems.
More Details: https://arxiv.org/abs/2502.11946