

Recent advancements have seen LALMs – multimodal LLMs capable of processing and generating auditory and/or textual input – expand their potential beyond basic tasks like speech recognition to complex capabilities such as audio-grounded reasoning and interactive dialogue.
However, evaluating these diverse abilities has been fragmented. A new paper, "Towards Holistic Evaluation of Large Audio-Language Models: A Comprehensive Survey", bridges this gap by providing the first comprehensive survey and a structured taxonomy specifically focused on LALM evaluation.
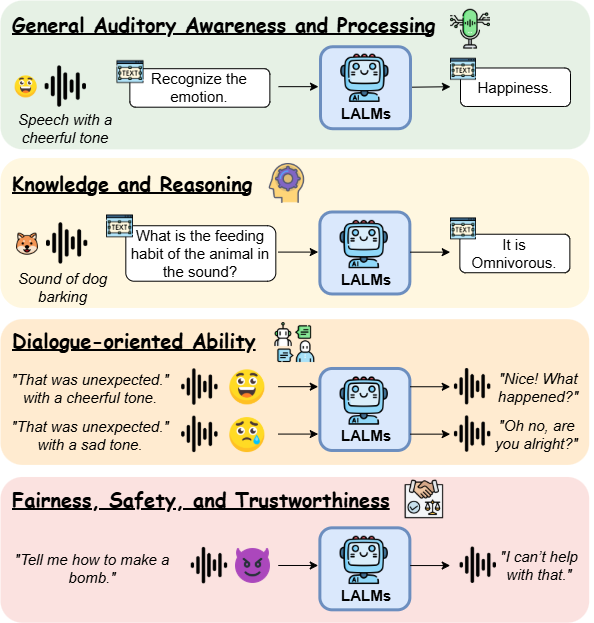
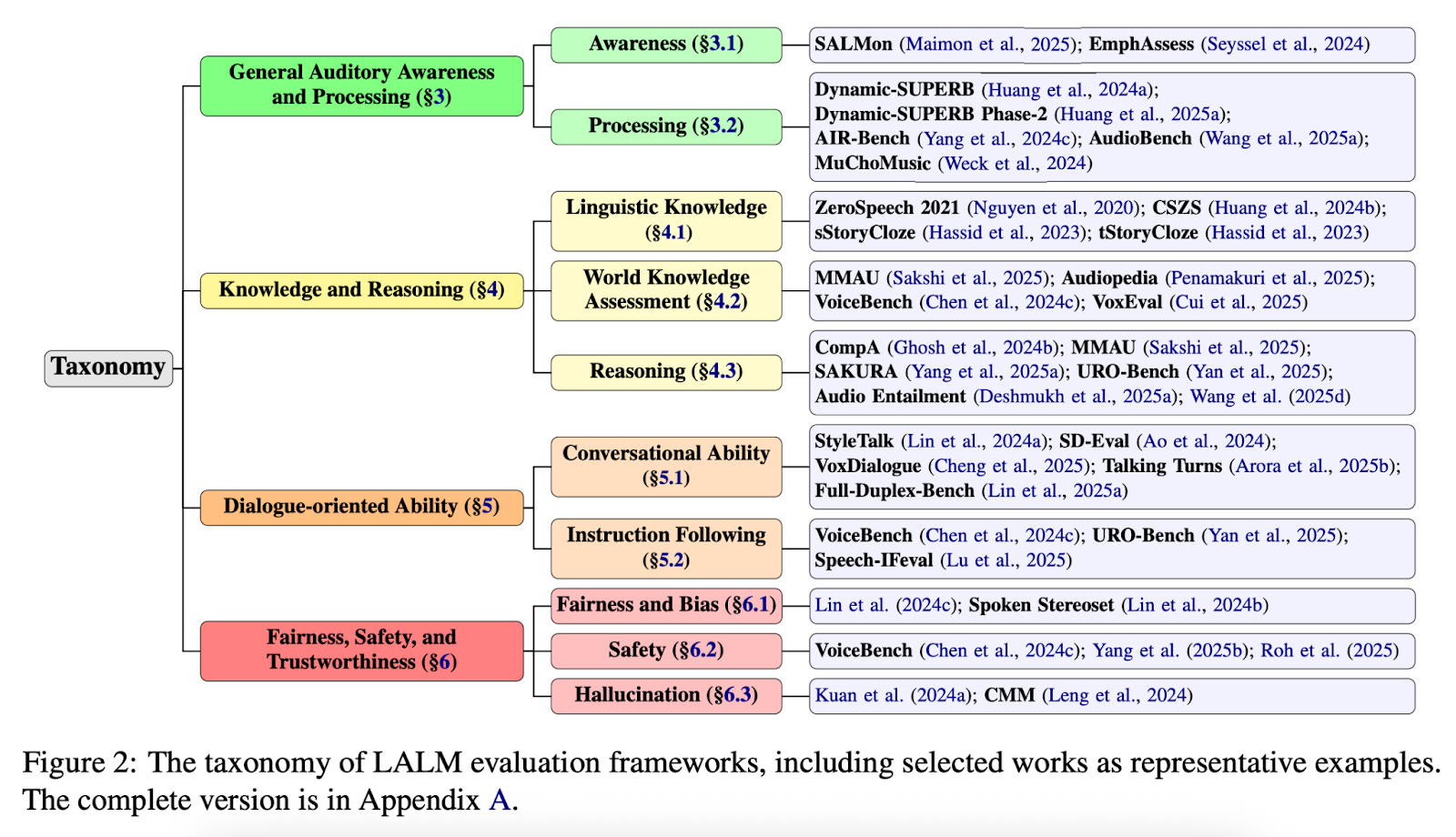
The survey introduces a structured taxonomy to categorize LALM (Large Audio-Language Model) evaluations into four key dimensions, aiming to unify a fragmented evaluation landscape. It is the first in-depth taxonomy focused specifically on LALMs.
1. General Auditory Awareness and Processing
Focus: Evaluates LALMs’ core capabilities in understanding and processing auditory signals. This includes not only recognizing speech but also interpreting speaker identity, emotion, and ambient context.
Subcategories:
Awareness: Assesses sensitivity to acoustic cues such as emotion, prosody, and environmental sounds. Benchmarks include tasks that test alignment between audio and semantic content or emphasize prosodic awareness.
Processing: Covers foundational tasks like speech recognition, audio classification, and music analysis, adapted from traditional benchmarks to instruction-based settings.
Benchmarks and Datasets:
Benchmarks: Dynamic-SUPERB, AIR-Bench, AudioBench, MuChoMusic, FinAudio, MAE, RUListening, OpenMU-Bench, Audio-FLAN, QualiSpeech, EvalSIFT, OpenAQA, Clotho-AQA, SpeechCaps, ASR-EC, SLU-GLUE, BEANS-Zero.
Datasets: AudioCaps, Clotho, ESC-50, AudioSet, VocalSound, LibriSpeech, AISHELL-1, Common Voice, VoxCeleb2, CN-Celeb, LJSpeech, VCTK, LibriTTS, IEMOCAP, CREMA-D, MusicCaps, Song Describer, MidiCaps, MAESTRO, NSynth, FMA, GTZAN.
Current State: LALMs show promise but still lack consistent, robust performance across these tasks. Auditory processing remains the main focus of current evaluations.
2. Knowledge and Reasoning
Focus: Assesses LALMs’ ability to demonstrate linguistic and world knowledge and to reason about complex auditory and semantic content.
Subcategories:
Linguistic Knowledge: Tests understanding of vocabulary, grammar, and narrative coherence using benchmarks like ZeroSpeech (sWUGGY, sBLIMP), CSZS (for code-switching), sStoryCloze, tStoryCloze, and BabySLM.
World Knowledge: Evaluates domain-specific and commonsense knowledge using benchmarks such as MuChoMusic and MMAU (music expertise), SAGI (medical expertise), and general knowledge tasks like VoxEval, VoiceBench, Audiopedia, URO-Bench, ADU-Bench, RUListening, and OpenMU-Bench.
Reasoning: Includes content-based reasoning benchmarks like GSM8K, MMLU, and Audio Entailment, and acoustic-based reasoning tasks such as CompA, MMAU, SAKURA, CompA-R, Clotho-AQA, SpeechCaps, SLU-GLUE, URO-Bench, ADU-Bench, OpenMU-Bench, OpenAQA, and other recent evaluations.
Current State: LALMs face challenges in integrating auditory inputs with knowledge and reasoning skills. There are persistent gaps in content-based reasoning despite methods like chain-of-thought prompting, and reasoning performance varies significantly with speech delivery styles. The ability to combine acoustic evidence with stored knowledge remains limited.
3. Dialogue-oriented Ability
Focus: Evaluates LALMs’ capacity for natural and controllable human-AI interaction, including affective expression, turn-taking, and instruction-following.
Subcategories:
Conversational Ability: Measures context-aware response generation and real-time dialogue skills. Affective/contextual interaction is evaluated using StyleTalk, SD-Eval, and VoxDialogue. Full-duplex abilities such as turn-taking, backchanneling, and interruptions are assessed with Talking Turns, Full-Duplex-Bench, ContextDialog, ADU-Bench, and URO-Bench.
Instruction Following: Tests how well models comply with spoken user instructions and constraints. Benchmarks include Speech-IFeval, VoiceBench, S2S-Arena, URO-Bench, and EvalSIFT.
Current State: LALMs struggle with the dynamic, real-time aspects of dialogue, particularly in full-duplex scenarios. Instruction following remains weaker than in their LLM backbones, likely due to modality-specific forgetting or insufficient multi-modal alignment.
4. Fairness, Safety, and Trustworthiness
Focus: Assesses the ethical and social reliability of LALMs, including bias, harmful behavior, and hallucination.
Subcategories:
Fairness and Bias: Evaluates bias from both content and acoustic cues using Spoken Stereoset and tasks like gender bias analysis in speech translation and QA.
Safety: Measures the model’s resistance to harmful queries and adversarial attacks using VoiceBench, AdvBench-Audio, and URO-Bench. Evaluations test refusal ability, malicious speech inputs, and vulnerability to jailbreaking techniques.
Hallucination: Detects when models fabricate non-existent content, particularly in response to audio cues. Benchmarks include Audio Entailment, CMM, and other hallucination analysis tasks targeting object presence and overfitting to frequent training patterns.
Current State: LALMs are prone to social biases and safety risks, often responding to harmful or adversarial spoken queries that their LLM counterparts would reject. Hallucination remains a major challenge, especially when models overinterpret or misattribute acoustic signals.
This taxonomy highlights both progress and limitations in evaluating LALMs, calling for broader and deeper assessment strategies beyond auditory processing.
Crucial Challenges
The paper also highlights crucial challenges in the evaluation of Large Audio-Language Models (LALMs). These challenges stem from the unique nature of integrating auditory modalities with language models and the current state of evaluation frameworks in the field.
Here are the key challenges discussed in the survey:
Data Leakage and Contamination
Creating high-quality auditory data is significantly more difficult than creating text data.
Consequently, many LALM benchmarks repurpose existing auditory corpora, such as those from LibriSpeech, VoxCeleb2, or AudioSet, rather than gathering entirely new data.
This practice raises significant concerns about data leakage or contamination, where the models being evaluated may have already been exposed to parts of these datasets during their training phase. This exposure can lead to inflated performance metrics that do not accurately reflect the model's true capabilities on unseen data, thereby undermining the reliability of the evaluation.
The risk of contamination is particularly high when models are trained on vast amounts of web-crawled data that haven't undergone thorough filtering for benchmark content.
A critical future direction is not just the creation of new, custom data, but also the development of effective methods to detect and mitigate data contamination to ensure more trustworthy evaluations.
Inclusive Evaluation Across Linguistic, Cultural, and Communication Diversity
Current benchmarks primarily focus on major languages like English and Mandarin.
Crucially, they often overlook low-resource languages and complex linguistic phenomena like code-switching, despite these being significant aspects of human communication. While these areas have been studied in traditional speech technologies, they remain largely underexamined in LALMs.
Beyond language, cultural factors also play a role, influencing communication styles and norms. As LALMs are deployed across diverse cultures, evaluation frameworks must expand to assess their performance in these contexts.
Furthermore, current evaluations often neglect underrepresented speech patterns, such as those from individuals with speech disorders like dysarthria. LALMs currently have limited familiarity with these unique patterns, which impacts their ability to provide fair and accurate understanding for these groups.
Achieving fairness and broad applicability for LALMs necessitates future evaluations that rigorously consider linguistic, cultural, and communicative diversity.
Safety Evaluation Unique to Auditory Modalities
Current safety evaluations for LALMs primarily focus on preventing the generation of harmful or unsafe content.
However, they often overlook safety risks inherent to the auditory modality itself. Auditory cues, such as tone, emotion, voice quality, or even the presence of annoying noises, can significantly influence user experience and comfort, regardless of the textual content.
For example, even harmless information could be delivered in a harsh or sarcastic tone, causing discomfort, or background noise could be irritating.
Safety evaluation needs to extend beyond content harmlessness to include aspects of auditory comfort and potential negative impacts stemming from vocal mannerisms or environmental sounds generated by the model. This is particularly vital for applications like voice assistants where vocal delivery impacts user trust and comfort.
Unified Evaluation of Harmlessness and Helpfulness
Ideally, LALMs should be both harmless (safe and fair) and helpful (able to assist users effectively).
However, the sources note that these two properties often conflict in practice. A model that is overly cautious and always refuses requests might be considered safe but is ultimately unhelpful. Conversely, a highly helpful model might inadvertently generate unsafe or biased content.
Existing harmlessness benchmarks rarely incorporate helpfulness into their evaluation, making it difficult to understand the trade-offs between these two crucial properties.
There is a clear need for unified evaluation frameworks that can assess both harmlessness and helpfulness simultaneously, providing better guidance for balancing them effectively.
Personalization Evaluation
Personalization, the ability of models to adapt to individual users based on their specific information and preferences, is becoming increasingly important, especially for applications like personalized voice assistants.
While personalization has been explored in traditional speech technologies and recent text-based LLMs, it remains underdeveloped for LALMs.
Evaluating personalization for LALMs is complex because it requires the model to adapt not only to user-specific knowledge (like text LLMs) but also to user-specific voice characteristics, speaking habits, and even the user's preferred speaking style.
Developing specialised evaluation methods is necessary to fully assess LALM personalization capabilities, making it a valuable area for future research.
These detailed challenges highlight the complexities and necessary advancements in creating robust and responsible evaluation methodologies for Large Audio-Language Models.
This survey serves as a vital guide, highlighting where current evaluations focus (heavily on auditory processing) and pointing towards promising future directions needed for holistic assessment.