
Revolutionizing Text-to-Speech: How Differentiable Reward Optimization is Changing the Game
This paper presents a Differentiable Reward Optimization method to enhance the performance of neural codec language model-based text-to-speech systems by directly predicting rewards from neural codec

Paper
The world of text-to-speech (TTS) synthesis has been transformed by large language models, but training these systems to produce high-quality, controllable speech has remained a significant challenge. Traditional reinforcement learning from human feedback (RLHF) approaches for TTS are computationally expensive and complex. However, groundbreaking research from Alibaba's Tongyi Lab introduces a novel solution: Differentiable Reward Optimization (DiffRO).
The Problem with Traditional TTS Training
Current neural codec language model-based TTS systems face several hurdles when implementing RLHF:
Computational Overhead: Unlike text-based language models, TTS systems require additional backend flow matching and vocoder models to convert discrete tokens into audio. This creates a massive computational burden when generating training data.
Limited Sample Diversity: Generated TTS samples often exhibit high similarity, making it difficult to distinguish between positive and negative examples for reward model training.
Complex Evaluation: TTS quality depends on multiple factors—pronunciation accuracy, naturalness, speaker similarity, and emotional expression—making simple binary classification insufficient.
Introducing DiffRO: A Paradigm Shift
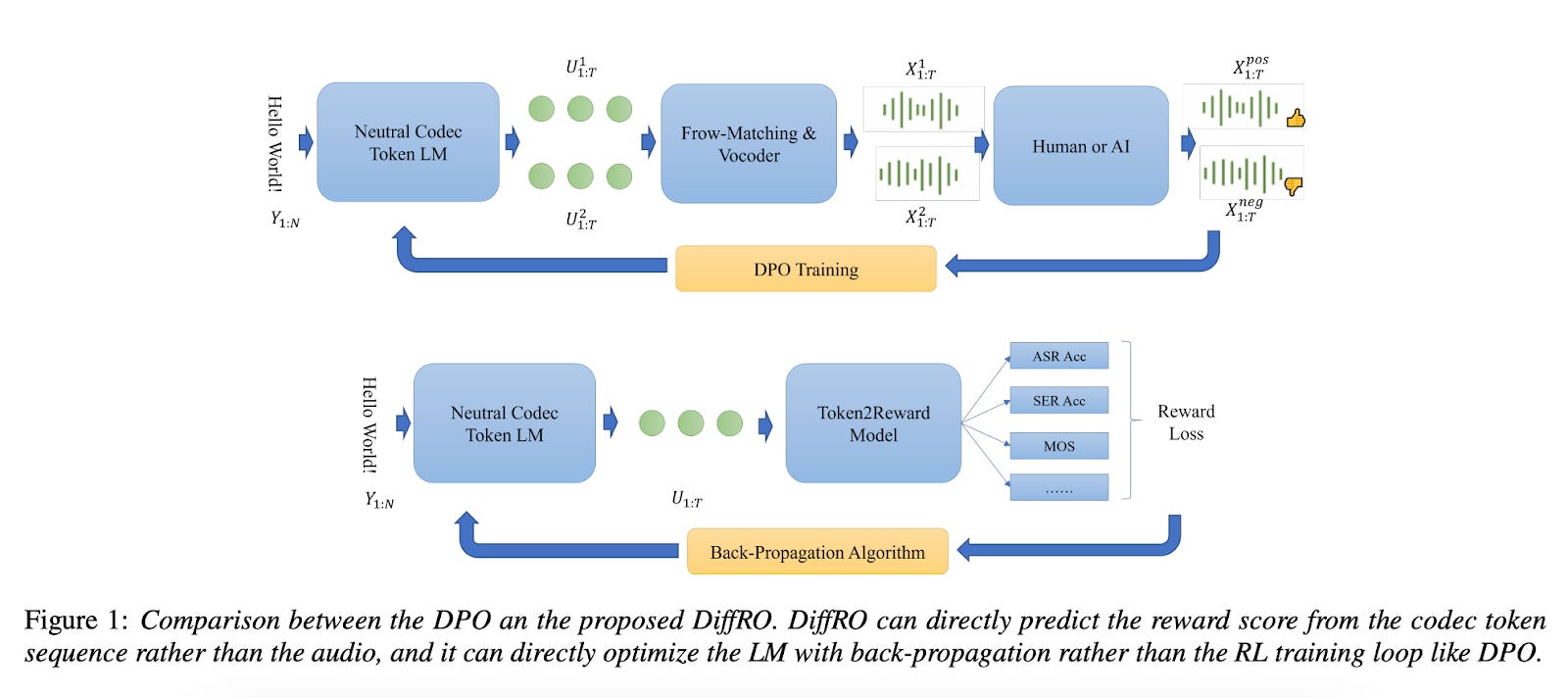
DiffRO addresses these challenges through three key innovations:
1. Token-Level Reward Prediction
Instead of synthesizing audio to evaluate quality, DiffRO predicts rewards directly from neural codec tokens. This approach leverages the fact that codec tokens should contain all necessary information from the input text. By using an ASR-style approach to predict the original text from tokens, the system can assess pronunciation accuracy without expensive audio synthesis.
2. Differentiable Training Process
Traditional RLHF requires complex reinforcement learning loops. DiffRO uses the Gumbel-Softmax technique to make the reward function differentiable, enabling direct optimization through standard backpropagation. This eliminates the need for Proximal Policy Optimization (PPO) or Direct Preference Optimization (DPO) strategies.
3. Multi-Task Reward (MTR) Model
Rather than focusing solely on pronunciation, DiffRO employs a multi-task reward model that simultaneously handles:
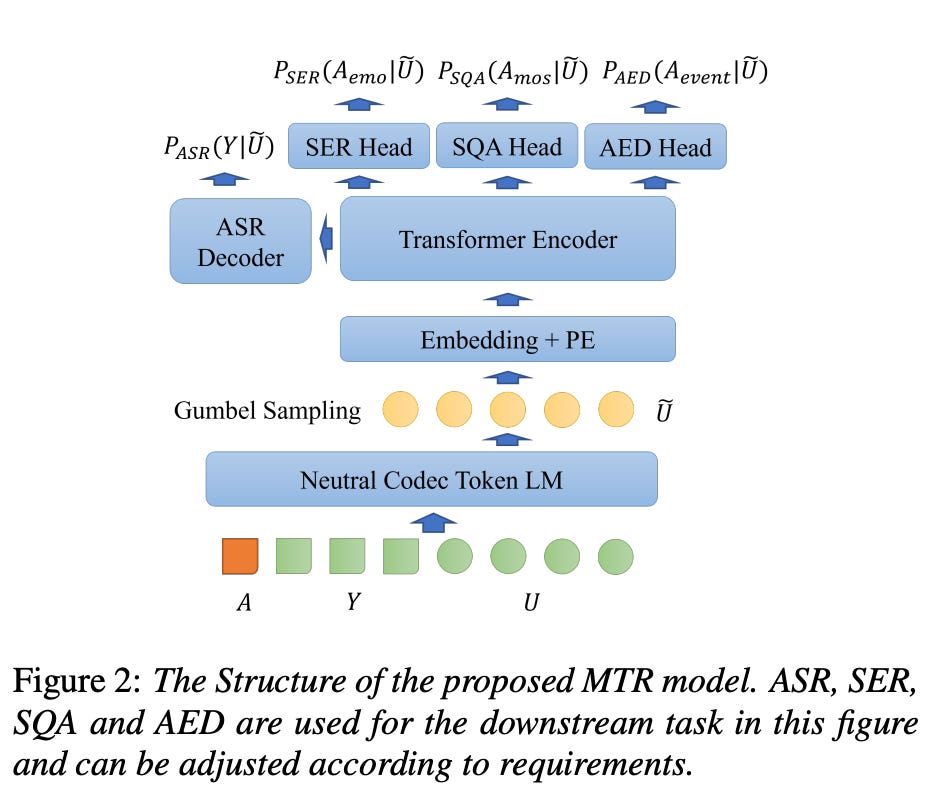
Automatic Speech Recognition (ASR) for pronunciation accuracy
Speech Emotion Recognition (SER) for emotional expression
Speech Quality Assessment (SQA) for overall audio quality
Age and Gender prediction for speaker characteristics
Impressive Results Across Multiple Dimensions
The researchers tested DiffRO on the challenging seed-tts-eval benchmark, demonstrating significant improvements across multiple languages and evaluation criteria:
Pronunciation Accuracy: The system achieved state-of-the-art word error rates across Chinese, English, and challenging text cases, with particularly impressive results on hard-to-pronounce content.
Cross-Lingual Performance: Remarkably, DiffRO improved performance on Japanese and Korean without language-specific training data, suggesting the method helps models learn universal pronunciation principles.
Emotional Control: The multi-task approach enabled sophisticated emotional expression control, with the system achieving high accuracy across Happy, Sad, and Angry categories. Most impressively, the model learned to generate natural audio events like laughter and breathing sounds without explicit training.
Competitive Performance: DiffRO outperformed existing models including F5-TTS and GPT-SoVITS on emotion benchmarks, demonstrating its practical superiority.
Beyond the Technical Achievement
What makes DiffRO particularly exciting is its potential to democratize high-quality TTS development. By reducing computational requirements and simplifying the training process, this approach makes advanced speech synthesis more accessible to researchers and developers with limited resources.
The method's ability to control multiple speech attributes simultaneously—from pronunciation accuracy to emotional expression—opens new possibilities for personalized AI assistants, content creation tools, and accessibility applications.
Looking Forward
While DiffRO represents a significant leap forward, the researchers acknowledge areas for future development. The current approach primarily optimizes the language model component, while speaker-related attributes are more heavily influenced by the flow matching and vocoder stages. Future work aims to extend DiffRO to these components for even more comprehensive control.
The success of DiffRO suggests we're entering a new era of efficient, controllable speech synthesis. As the demand for natural, emotionally-aware AI interactions continues to grow, methods like DiffRO will be crucial for building the next generation of voice-enabled applications.
This research represents a fundamental shift in how we approach TTS optimization, moving from expensive, complex training procedures to efficient, direct optimization methods. The implications extend far beyond technical improvements—they point toward a future where high-quality, controllable speech synthesis becomes a standard capability rather than a specialized achievement.